

XCentium Blogs
Technical
Using Open source User function libraries in Qubole Hive
I’m hoping to keep it basic enough for new users, but I make the following assumptions:
- You know enough about Qubole that you can get get around in the Analyze and Control Panel pages.
- You will be using a non-trial Qubole account, so that you can alter the Hive bootstrap.
- You understand the basics of Hive functions.
If you want to know the basics of Qubole, you can sign up for a free account from their home page.
If you’d like to know more about types of functions in Hive, start [here](https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-HiveOperatorsandUser-DefinedFunctions(UDFs) #LanguageManualUDF-HiveOperatorsandUser-DefinedFunctions(UDFs)).
If you’d like to know more about developing your own custom functions in Hive, start here. It has links to some more complicated examples.
Here are the steps to use an open source library of user functions in Qubole to extend Hive.
Download an open source function library jar file:
For this example, we’re going to use the Brickhouse library which contains a variety of useful [functions](https://github.com/klout/brickhouse/wiki/UDF-Overview "Function Overview"). It’s been around for several years and has some fans.
The first thing you have to do is make sure the library will work with the version of Hive you’re using. The main page indicates that Hive 0.9.0 is required, so that will work with the current version of Qubole, which is a higher version.
One way to get the library is to download it as source code and build the jar files. This is certainly doable; but it would be difficult to write a good blog about it. This is because how you do it step-by-step is somewhat different in various operating systems. The advantage of downloading/building is it gives you the most up-to-date code. There is an outline of how to do this in the Brickhouse pages, if you want to try. There are also decent examples on the web of how to work the various steps they mention, like downloading and using Git, the JDK and Maven.
The easier way of getting this library is to download pre-built JAR files. To do this, get the most recent version from the Brickhouse downloads page. This blog uses version 0.6.0.
There are 3 different files for version 0.6.0, identified by the suffix before the “.jar” filename suffix. For the example, we’ll only use the brickhouse-0.6.0.jar file, not the *-sources.jar or *-javadoc.jar files.
Upload the jar file to an S3 location available to your Qubole cluster:
Having the jar file on our local drive, we need to put it into S3. And it needs to be accessible by the AWS account used by the cluster where you’re going to run Hive.
For the example, I created an “external jars etc” folder in our xcentium-hadoop bucket. Then I copied the jar file there. I used Cloudberry Explorer (Freeware version for Windows), but any of the tools available to transfer local data to S3 will do the job.
Make the library available for Hive queries:
There are 3 ways of making this library available on the Qubole cluster when executing Hive queries. Option 1: You can direct Hive to get this jar file and use it for just this query. You do this by putting an “add jar” statement at the top of your Hive query as shown below. This option is good for testing and for jars that are not commonly-used.
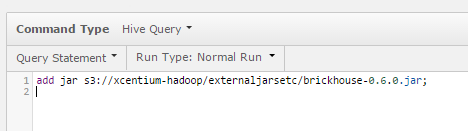
Option 2: You can add the jar file to a bootstrap script Qubole runs before every Hive query. This is useful when many queries are dependent on the function.To do this:
1. In the Qubole website, click the Control Panel icon entry on the left-side navigation.
2. Click the Hive Bootstrap tab.
3. Copy the “add jar” statement to the editor as shown, and save.
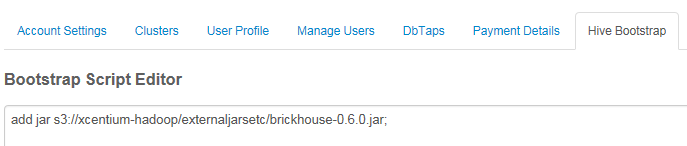
Option 3: You should be able to copy the jar file to the folder on the Qubole nodes that contain all the Hive jar files by means of a cluster bootstrap script. This is an advanced measure with a minimal advantage over Option 2. I won’t describe how to do this as it would make this blog entry much longer.
Use a function from the library in a Hive query:
Now that we have the “add jar” statement set up, one or more functions within the jar file can be referenced and used. This sometimes takes a little bit of research, so I’ll explain how I got the various components. If you're using another library, the process will be different.
I discovered this library while looking for an alternative to self-joining rows in Hive. The page I found mentioned the “collect” function as being an alternative to self-joining -- which can be very slow. I had the source code for the library and knew I needed a “create temporary function” statement, so I searched for that string and the word “collect”. That got me an .hql (Hive-QL) file with a list of all the function creation statements. I would have had the same luck searching for the same text, plus “brickhouse” on the web. That search returns the same file in Github.
Then it was a matter of working the documentation to see how the Collect function worked. I found an example and experimented with it until I understood that collect can be used with a column and produces an array/list of that column’s values at the Group By level.
With that, I could write the code to use this function, which you’ll see below.
- The “use” statement means I’m can query a Hive database we’ve set up for e-commerce demos.
- The “add jar” statement is explained above. It’s commented out because this library is in my Hive bootstrap (Option 2 above).
- The “create temporary function” statement says I have a function I’ll call “collect” that will use a function in the string referred to in the single quotes. (This can also go in the bootstrap script file, if you use it frequently.)
- The Select statement groups a table of order items by order id and returns a result containing the order and an array of the pids (product ids). I’m only showing the orders with more than 1 order item and only showing 10 for this example.
The result is below. The items “018JDFF-200344” are the order ids and items like [“4196”,”11414”] are the arrays of pids.
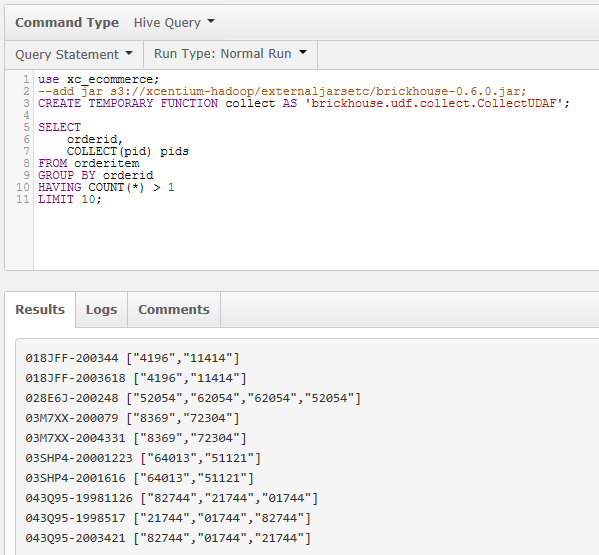
Conclusion:
From this example, you can see it is not difficult to use an open source user function library with Qubole/Hive. There appear to be a few other useful libraries out there. And you can write your own -- perhaps a future blog entry. The first 3 steps (download, put on S3, make available to Hive) are also useful for adding Hive SerDes or compression libraries.