
Type

XCentium Blogs
Technical
Automated Data Migration in Salesforce B2B Commerce Cloud
Dealing with the exporting and importing of data when refreshing sandboxes is an issue that most SFDC orgs wrestle with. In Salesforce B2BCommerce, this entails base migration of three objects relating to configuration of the application, as well as secondary (but still required objects) for Page Labels, Page Sections, Products, Price Lists, and Specs (just to name a few).
In terms of the impact of having to manage those records after refreshing a sandbox, the process of manually exporting the data from a source environment (typically Production) and then importing that data while maintaining the relationships (both direct and indirect) is often a challenge. Considering that this is a repetitive and mostly static process, data migration is clearly a candidate for automation.
While there are a few third-party products out there that offer varying degrees of solutions to this dilemma - I've developed a proof of concept that leverages the Metadata API and Static Resources to allow a configurable solution that can be implemented not only from a typical production-to-sandbox scenario, but from sandbox-to-sandbox or sandbox-to-production.
The approach relies on the fact that Static Resource files are automatically deployed from the source environment to the target environment. Often, these resources are Javascript, CSS, or images that are leveraged by Visualforce pages, however we can store a file that is otherwise unrelated to this typical use case; for example, such as storing records as JSON text.
Since DML operations cannot be performed on Static Resources using Apex DML operations, I leveraged an Apex implementation of the Metatdata API to manage the creating, updating, and destruction of the JSON-stored records. A simple utility class serves as a generic handler for these operations and can be called from an anonymous Apex script, or a class that implements the Schedulable interface (to name two).
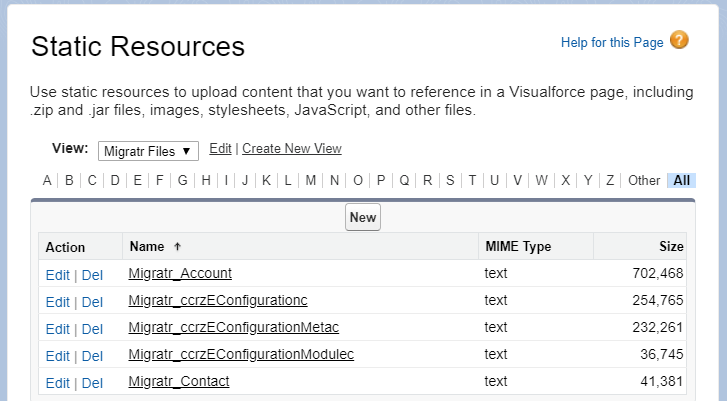
To respect limitations on data storage (specifically for Developer-type sandboxes), I created a Custom Setting that is used as a configuration tool to determine which objects should be collected, and if desired, a limit on the number of records to query and store. There is also a numeric Sequence__c field that can be leveraged to determine the order in which records are created in the target environment.
The handler responsible for the collection of records queries this custom setting record and runs an effective what amount "SELECT *" query for each, storing the result as JSON text in a Static Resource.
In order to be able to maintain the connections between related objects, must have an new Text External Id field added, called XC_Id__c. When querying the fields, if this value is not set, then the records’ Ids are stored in this field (without performing DML on the original records). This field is then used by the downstream process to make the connections of the dependent data that has been inserted.
A second utility class handles the downstream process that creates the record stored in the Static Resource files. This class implements the SandboxPostCopy Interface, which allows it to be specified when creating/refreshing a sandbox.
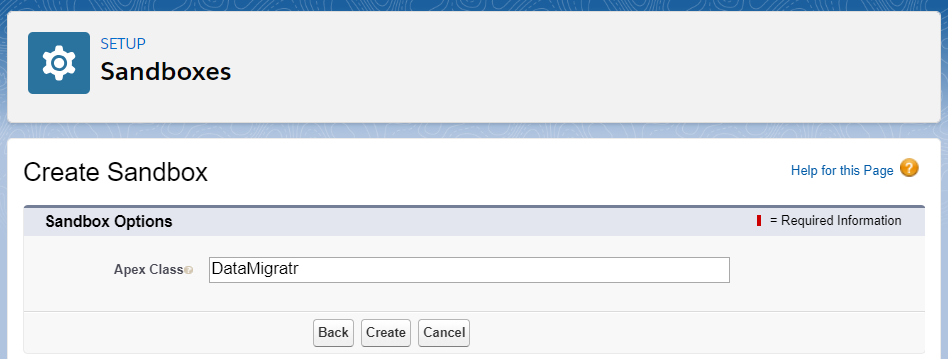
Since this solution will eventually see use in more mature Salesforce orgs (with an n-number of potential objects and records), both the query/store and the read/insert utilities implement the Queueable interface to manage the limits inherent in dealing with these large data sets.

Senior Salesforce Developer